






KJR Chosen to Test Microsoft Azure’s ‘Public Sector Information Assistant’
Microsoft’s recent Delta version launch brings forth a revolutionary platform designed to empower Public Sector Institutions with the capabilities of ChatGPT v4.
In recognition of KJR’s expertise in software testing, Microsoft extended an exclusive invitation to refine their cutting-edge tool known as the ‘Public Sector Information Assistant.’
This collaboration highlights Microsoft’s recognition of KJR’s extensive expertise in software quality assurance, entrusting us with the crucial responsibility of testing a platform poised to refine data interaction.
This blog post delves into the highs and lows of our testing experience for Microsoft and sheds light on the approach we adopted to evaluate this innovative tool.
The Platform’s Purpose and Potential
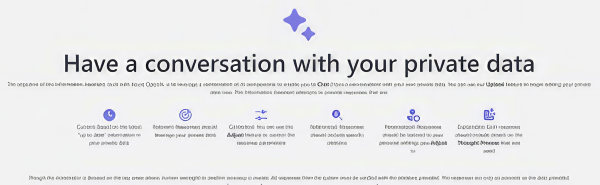
The ‘Public Sector Information Assistant,’ built with Azure OpenAI, is a chatbot poised to redefine data interaction. The platform leverages the power of generative AI large language models to let Public Sector employees or customers have meaningful conversations with their data, using the advanced capabilities of ChatGPT v4. The potential applications span diverse scenarios, from technical inquiries by defense employees to students seeking tailored information about their study programs.
The primary goal of the Information Assistant is to provide precise, reliable, and current information to Public Sector employees and customers for their inquiries. It responds to prompts by drawing on an internal knowledge base comprised of specific documents (the platform currently accepts PDFs only). Additionally, the platform provides context and citations, offering transparency into the origin of the information.
This Microsoft tool is a fusion of code, internal documentation, and educational resources. It serves as a foundational element for constructing customer-centric AI capabilities, opening avenues for enhanced interactions.
Platform Testing with KJR
With over 25 years’ experience in software quality assurance and risk management, KJR has extensive knowledge in government IT services. Our goal is to ensure government technology functions seamlessly, remains compliant, and serves the best interests of Australian citizens.
We conducted a thorough examination of the platform using our proprietary data to pinpoint and rectify errors. Employing a combination of manual and automated testing, we aimed to ensure the precision of responses.
The testing scope for the Azure Open AI chatbot involved assessing contextual understanding, response relevance, document comprehension, and language understanding. The tests sought to determine the chatbot’s ability to accurately grasp and sustain the context of a conversation, deliver pertinent and precise responses across various prompts, correctly interpret and extract information from uploaded documents, and effectively handle invalid inputs or operational errors.
Testing Methodologies
The reliability of the Information Assistant rests on robust testing methodologies, combining manual scrutiny and automated precision at its core.
Manual Testing: It involved testing the accuracy of the chatbot’s answers after uploading a new document.
- Document Uploading: Various document types, including a mix of relevant and irrelevant internal documents, and those from external sources, were uploaded to the platform. This facilitated an assessment of its contextual understanding.
- Strategic Questioning: Varied questions, ranging from client queries to nuanced scenarios, including one recurrent question, were asked after each document upload to gauge the system’s adaptability and accuracy. Would the same answer be provided every time? Would the answer be adapted to/based on the new document uploaded – regardless of this document being relevant to the question – or would the answer be different based on the other prompts asked at the same time?
- Diverse Scenarios: A battery of tests, including case studies, policy manual uploads, and consultant profiles, ensured a comprehensive evaluation of the Information Assistant’s responsiveness.
Automated Testing:
- Using Scripts for Streamlined Evaluation: Automated testing was done with test scripts (list of prompts) to accelerate the evaluation process.
- Question Cataloging: A systematic approach to asking individual questions allowed for a streamlined examination of the system’s responses.
- Validation Stage: While automation sped up the process, a manual review of answers was necessary to ensure accuracy. Automation couldn’t cover this step due to the potential of providing technically correct but not contextually relevant answers. Keeping a human-in-the-loop approach maintained precision standards at the highest level.
Key Challenges
Even within the meticulous testing framework, challenges surfaced, providing invaluable insights into the intricacies of the system.
Navigating User Inputs
- Contextual Understanding: The Azure Open AI Chatbot consistently demonstrated a robust ability to grasp the context of conversations, effectively maintaining coherence throughout most instances.
- Error Handling: It managed invalid or ambiguous user prompts by providing a default response and, in some instances, seeking clarification.
Consistency and Relevance in User Outputs
- Response Consistency: Varied response patterns were noted, highlighting instances where the chatbot faced challenges in shifting contexts based on user prompts, occasionally causing confusion. Although the essence of the response remained intact, the structure and wording exhibited inconsistencies when users attempted to regenerate responses for the same prompt.
- Response Relevance: Responses, in general, were pertinent and accurate to user prompts, underscoring the chatbot’s capability to handle a diverse range of queries.
Prioritising and Understanding Uploaded Documents
- Priority System Dynamics: Recently uploaded documents were accessed while generating responses. This inclination towards prioritising the latest document sometimes resulted in unintended inaccuracies.
- Document Understanding: The platform displayed a robust capability to interpret and extract information from uploaded documents, limited to PDFs. However, instances where the chatbot misinterpreted information between documents led to providing invalid responses.
- Citation Accuracy: The Information Assistant exhibited occasional inaccuracies in providing citations, prompting a closer examination of data sourcing mechanisms.
Overall, the Azure Open AI chatbot has demonstrated impressive capabilities in contextual understanding, response relevance, document comprehension, and error management.
Its proficiency in maintaining conversation context and generating pertinent responses to diverse prompts is remarkable.
However, there are opportunities for enhancement. While it generally interpreted and extracted document information accurately, instances of misinterpretation and irrelevant references surfaced. Addressing these areas could significantly elevate the user experience and enhance the effectiveness of the chatbot.
Conclusion
Testing, as evidenced by our exploration of the Public Sector Information Assistant, is indispensable in ensuring the reliability and effectiveness of software solutions. It is a critical phase that not only uncovers potential challenges but also provides opportunities for refinement. The ability to identify contextual nuances, response inconsistencies, and areas for improvement exemplifies the value of rigorous testing in delivering a product that meets and exceeds user expectations.
As a leading software testing company, KJR is committed to assuring digital success. If you seek to optimise your software’s performance and user experience, connect with us today!